树链剖分能够将一棵树按照某种法则剖分为若干条链,从而便于维护树上路径的信息。
按照剖出链的法则不同,其性质也不同,大体可将树剖分成重链剖分,长链剖分和用于 Link-Cut Tree 的剖分(实链剖分)。
其中重链剖分用途最广泛,本文也只介绍重链剖分。
重链剖分
定义与部分性质
给出如下定义
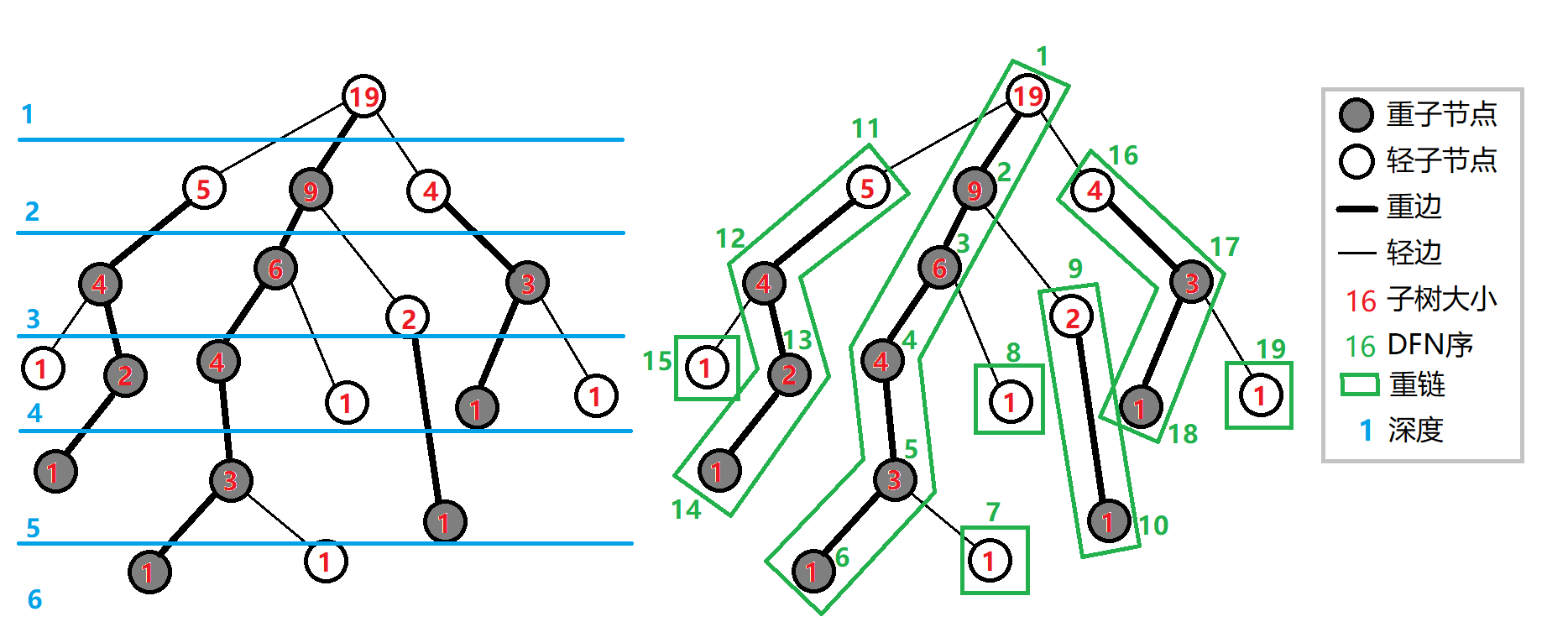
- 重儿子。对于一个非叶子节点,其重儿子为其以它的所有儿子为根的子树中,最大子树所对应的那个子节点。如果最大不唯一则任取其一。
- 轻儿子。对于一个非叶子节点,其重儿子之外的子节点都为轻儿子。
- 重边。一个节点到其重儿子的边。
- 重链。多条相连的重边构成的链,或者链接连续的重儿子的链。
- 轻边。连接两条重链的边。
- 链头。一条重链中深度最小的节点,其必定是轻儿子或根。
性质:同一条重链上的点,其 LCA 为链头。
重要性质:从叶子节点到根,最多经过 $O(\log_2 n)$ 条轻边(重链)。
证明:
考虑从叶子节点 $x$ 向上跳到根。如果 $x$ 在重链上,那么直接跳到链头。如果 $x$ 在轻边上,那么跳到的 $fa(x)$ 必然是一条重链的链头,由于重儿子不是 $x$,所以以其重儿子为根的子树大小加上 $sz(x)$,大小必然超过 $2sz(x)$。因此最多经过 $O(\log_2 n)$ 条轻边,而轻边链接重链,所以经过 $O(\log_2 n)$ 条重链。
也不难看出对于任意两点,其间路径长度也是 $O(\log_2 n)$。
求 LCA
- 如果 $x$ 与 $y$ 在同一条重链上,那么 $lca(x,y)$ 就是深度更小的那个点。
- 否则让所在链的链头深度大的那个点往上跳一条重链。
- 最后深度小的为 $lca(x,y)$。
由上述性质可知复杂度为 $O(\log_2 n)$。
代码如下
int lca(int x,int y) {
// top[x] x所在链的链头
// 如果x为轻儿子,则top[x]=x
// fa[x] x的父亲
// dep[x] x的深度
while(top[x]!=top[y]) {
if(dep[top[x]]<dep[top[y]]) swap(x,y);
x=fa[top[x]];
// top[x]跳到链头,fa[top[x]]跳到下一条链
}
return dep[x]<dep[y]? x:y;
}树上问题转化序列问题
如果在dfs的过程中优先访问重儿子,那么可以发现每一条重链 $dfn$ 是连续的,对应着序列上的一个区间。而轻儿子则相对封闭,对应着序列上的一个单点。
对于树上两点 $(x,y)$,其路径必然是 $x \rightarrow lca(x,y)$,$lca(x,y) \rightarrow y$。结合上面讲到的求 $lca$ 的方法,可以发现在这个过程中,每将那个点向上跳一步,就对应了一个区间,这些区间一定能不重不漏地覆盖此点到 $lca(x,y)$ 的所有点,跳完之后在一条重链上,而重链上两点之间路径的 $dfn$ 必然是一个区间。
因此,如果将 $dfn$ 看作序列,用序列上的数据结构来处理链信息,那么最多处理 $O(\log_2 n)$ 次。
这个数据结构一般是线段树。
还有一个 dfs 本身的性质,以 $x$ 为根的子树内,其所有 dfs 序构成一个区间 $[dfn(x),dfn(x)+sz_x-1]$。
因此能更快地维护子树信息。
code
dep[x],fa[x],top[x]意义同求 $lca$ 的那部分代码中。
son[x]表示节点 $x$ 的重儿子,sz[x]表示以 $x$ 为根的子树大小,id[x]表示节点 $dfn(x)$。
先用一遍dfs求出dep[x],fa[x],son[x],sz[x]。
void dfs1(int x,int fr) {
dep[x]=dep[fr]+1, fa[x]=fr;
sz[x]=1;
for(int i=h[x];i;i=nxt[i]) {
int y=to[i];
if(y==fa) continue;
dfs1(y,x);
sz[x]+=sz[y];
if(!son[x]||sz[son[x]]<sz[y]) son[x]=y;
}
}
signed main() {
dfs1(1,0);
}然后进行一次优先访问重儿子的dfs,求出id[x],top[x]。
void dfs2(int x,int tp) {
id[x]=++num, top[x]=tp;
if(!son[x]) return;
dfs2(son[x],tp);
for(int i=h[x];i;i=nxt[i]) {
int y=to[i];
if(y==fa[x]||y==son[x]) continue;
dfs2(y,y);
}
}
signed main() {
dfs2(1,1);
}然后
void upd(int x,int y) {
// 处理(x -> y)的点信息
while(top[x]!=top[y]) {
if(dep[top[x]]<dep[top[y]]) swap(x,y);
/*
此时[id[top[x]],id[x]]就是路径上的一个区间
这里用数据结构处理这个区间的信息
*/
x=fa[top[x]];
}
if(dep[x]>dep[y]) swap(x,y);
/*
此时x为lca
处理[id[x],id[y]]的信息
*/
}查询同上。
边权转化点权
上述操作都是建立在权值为点权的基础上的,不能直接解决边权问题。
考虑将边权转化为点权,一种方法是将边 $(x \rightarrow y)$,其中 $dep(x)<dep(y)$,其权值 $z$ 放到 $y$ 上。
如图。


可以发现如果要求得 $x$ 到 $y$ 的链信息,就要忽略 $lca(x,y)$ 的点权。
那么在修改和查询的时候忽略 $lca$ 就可以了。
也就是说
void upd(int x,int y) {
// 以上省略
if(dep[x]>dep[y]) swap(x,y);
/*
此时x为lca
处理[id[x],id[y]]的信息
改为
处理[id[x]+1,id[y]]的信息
*/
}luogu7735 轻重边
题目里的「轻重边」只是一个新定义,不如用 $0$ 边和 $1$ 边代替。
发现如果局限于 0/1 两种状态的话并不好做。
不难发现如果 $(x \rightarrow y)$ 是 $1$ 边,那么 $x$ 与 $y$ 一定同时在某一次操作的链上,可以看作是同一次被覆盖。
然后这个显然是充要的。
如果把每个节点被覆盖的颜色看作点权,那么问题等价于路径上有多少相邻点的点权相同。考虑树剖然后用线段树维护。
如何维护?记录区间左右端点的被覆盖的颜色,然后就合并就行了。叶子节点的初始颜色为其 $dfn$,这样就能保证初始不存在 $1$ 边。
还有一个问题,要得到路径上轻边左右端点的信息,也就是要单点查询id[top[x]]和id[fa[top[x]]]的颜色。
#include<bits/stdc++.h>
using namespace std;
#define SET(a,b) memset(a,b,sizeof(a))
#define rep(i,j,k) for(int i=(j);i<=(k);++i)
#define per(i,j,k) for(int i=(j);i>=(k);--i)
int read() {
int a=0, f=1; char c=getchar();
while(!isdigit(c)) {
if(c=='-') f=-1;
c=getchar();
}
while(isdigit(c)) a=a*10+c-'0', c=getchar();
return a*f;
}
const int N=1e5+5;
int T, n, m, num, tim;
int sz[N], son[N], fa[N], top[N], dep[N], id[N];
int tot, h[N], to[N<<1], nxt[N<<1];
int t[N<<2], lt[N<<2], rt[N<<2], tag[N<<2];
void pushup(int x) {
lt[x]=lt[x<<1], rt[x]=rt[x<<1|1];
t[x]=t[x<<1]+t[x<<1|1];
if(rt[x<<1]==lt[x<<1|1]) ++t[x];
}
void maketag(int x,int l,int r,int k) {
t[x]=r-l, lt[x]=rt[x]=k;
tag[x]=k;
}
void pushdown(int x,int l,int r) {
if(tag[x]) {
int mid=(l+r)>>1;
maketag(x<<1,l,mid,tag[x]);
maketag(x<<1|1,mid+1,r,tag[x]);
tag[x]=0;
}
}
void build(int x=1,int l=1,int r=n) {
tag[x]=lt[x]=rt[x]=0;
if(l==r) { t[x]=0, lt[x]=rt[x]=l; return; }
int mid=(l+r)>>1;
build(x<<1,l,mid);
build(x<<1|1,mid+1,r);
pushup(x);
}
void modify(int L,int R,int k,int x=1,int l=1,int r=n) {
if(L<=l&&r<=R) { maketag(x,l,r,k); return; }
pushdown(x,l,r);
int mid=(l+r)>>1;
if(L<=mid) modify(L,R,k,x<<1,l,mid);
if(R>mid) modify(L,R,k,x<<1|1,mid+1,r);
pushup(x);
}
int query(int L,int R,int x=1,int l=1,int r=n) {
if(L<=l&&r<=R) return t[x];
pushdown(x,l,r);
int mid=(l+r)>>1;
int ans=0;
if(L<=mid) ans+=query(L,R,x<<1,l,mid);
if(R>mid) ans+=query(L,R,x<<1|1,mid+1,r);
if(L<=mid&&R>mid&&rt[x<<1]==lt[x<<1|1]) ++ans;
return ans;
}
int query2(int k,int x=1,int l=1,int r=n) {
if(l==r) return lt[x];
pushdown(x,l,r);
int mid=(l+r)>>1;
if(k<=mid) return query2(k,x<<1,l,mid);
else return query2(k,x<<1|1,mid+1,r);
}
void add(int x,int y) {
to[++tot]=y, nxt[tot]=h[x], h[x]=tot;
}
void dfs1(int x,int fr) {
dep[x]=dep[fr]+1, fa[x]=fr;
sz[x]=1;
for(int i=h[x];i;i=nxt[i]) {
int y=to[i];
if(y==fr) continue;
dfs1(y,x);
sz[x]+=sz[y];
if(!son[x]||sz[y]>sz[son[x]]) son[x]=y;
}
}
void dfs2(int x,int tp) {
id[x]=++num, top[x]=tp;
if(!son[x]) return;
dfs2(son[x],tp);
for(int i=h[x];i;i=nxt[i]) {
int y=to[i];
if(y!=fa[x]&&y!=son[x]) dfs2(y,y);
}
}
void upd(int tim,int x,int y) {
while(top[x]!=top[y]) {
if(dep[top[x]]<dep[top[y]]) swap(x,y);
modify(id[top[x]],id[x],tim);
x=fa[top[x]];
}
if(dep[x]>dep[y]) swap(x,y);
modify(id[x],id[y],tim);
}
int ask(int x,int y) {
int ans=0;
while(top[x]!=top[y]) {
if(dep[top[x]]<dep[top[y]]) swap(x,y);
ans+=query(id[top[x]],id[x]);
if(query2(id[fa[top[x]]])==query2(id[top[x]])) ++ans;
x=fa[top[x]];
}
if(dep[x]>dep[y]) swap(x,y);
ans+=query(id[x],id[y]);
return ans;
}
void solve() {
n=read(), m=read();
tot=num=0, tim=n;
rep(i,1,n) h[i]=son[i]=0;
rep(i,1,n-1) {
int x=read(), y=read();
add(x,y), add(y,x);
}
dfs1(1,0);
dfs2(1,1);
build();
while(m--) {
int op=read(), x=read(), y=read();
if(op==1) ++tim, upd(tim,x,y);
else printf("%d\n",ask(x,y));
}
}
signed main() {
T=read();
while(T--) solve();
}参考
《算法竞赛》 By 罗勇军,郭卫斌